Buenos días postgreros y postgreras, en el día de hoy traemos para ustedes una entrada de nivel avanzado. No todo podía ser para los iniciados, claro está. Hoy estaremos poniendo en práctica una de las herramientas más útiles de PostgreSQL: repmgr. En esta entrada se va a simular un caso de conmutación por error (failover), es decir, hacer que un servidor esclavo se convierta en maestro de forma automática; failover con repmgr. Para ello utilizaremos la herramienta de código libre llamada repmgr.
Para probar este ejemplo se ha creado en una máquina ubuntu tres instancias de PostgreSQL (clúster), un servidor maestro y dos servidores esclavos.
¡Manos al teclado!
Instalación PostgreSQL
En mi caso, los tres servidores de PostgreSQL 9.6, residen en el localhost y cada uno de ellos en un PGDATA y en un PGPORT diferente.
- Servidor maestro: el PGDATA es /postgres/maestro y el PGPORT es 5430.
- Servidor esclavo1: el PGDATA es /postgres/esclavo1 y el PGPORT es 5435.
- Servidor esclavo2: el PGDATA es /postgres/esclavo2 y el PGPORT es 5440.
Instalación repmgr
Se ha instalado repmgr 3.3.2 mediante el código fuente. Para ello hay que compilarlo e instalarlo.
Observaciones
En el caso de que se haya modificado la ruta del directorio bin, hay que editar los archivos Makefile antes de compilar.
Configuración de PostgreSQL
postgresql.conf
Se ha configurado el clúster principal de PostgreSQL para hacer uso de la replicación mediante el archivado continuo junto a Streaming replication.
También se ha editado el parámetro shared_preload_libraries quedando de la siguiente forma:
shared_preload_libraries = 'repmgr_funcs'
pg_hba.conf
Antes de editar el archivo de autenticación de PostgreSQL, se crea un usuario llamado “repmgr” y una base de datos con el mismo nombre. El propietario de ésta base de datos debe ser el usuario “repmgr”.
Añadir una línea para la conexión incluyendo el usuario “repmgr” y la base de datos “repmgr”, y otra línea para la replicación.
repmgr.conf
En mi caso, debido a que tengo los tres servidores de Postgres en una misma máquina, he creado un archivo de configuración de repmgr por cada nodo (servidor).
- En cada archivo se le indica un nombre para el cluster que ha de ser igual para todos los nodos.
- Un número identificador y un nombre para el nodo, diferente para cada uno.
- La línea de conexión que incluye el host, el puerto, la base de datos y el nombre del usuario.
- Para que la conmutación por error se realice de forma automática, hay que editar el parámetro “failover”, los parámetros “promote_command” y “follow_command”.
Para que tengáis una referencia de como debe de quedar el archivo os dejo un ejemplo.
cluster=test
node=1
node_name=node1
conninfo='host=localhost port=5430 dbname=repmgr user=repmgr'
pg_bindir=/postgres/bin/
failover=automatic
promote_command='repmgr standby promote -f /postgres/repmgr.conf'
follow_command='repmgr standby follow -f /postgres/repmgr.conf -W'
Failover con repmgr en nuestra máquina
Iniciar los servidores de PostgreSQL
Una vez que ya tenemos las configuraciones de los servidores, se procede a levantar el servidor principal y registrar el maestro.
Para registrar el servidor como maestro se ejecuta un comando similar a la siguiente línea:
repmgr -f /postgres/repmgr.conf master register

Lo siguiente a realizar es levantar cada uno de los servidores esclavos y clonar los servidores de standby. Posteriormente hay que registrar cada uno como servidor esclavo, para ello, en mi caso hay que realizar lo siguiente:
Para clonar el servidor esclavo ejecuto la siguiente línea:
repmgr -p 5435 -h localhost -d repmgr -U repmgr -f /postgres/repmgr2.conf --force standby clone
Para registrar el servidor como standby se ejecuta un comando similar a la siguiente línea:
repmgr -f /postgres/repmgr2.conf standby register
Realizar los mismos pasos para el otro servidor esclavo.
Iniciar el proceso repmgrd que supervisa el clúster de servidores en cada servidor esclavo.
repmgrd -f /postgres/repmgr2.conf --verbose > /repmgr_log.log 2>&1
Con esta sentencia podemos ver los diferentes nodos registrados, donde vemos el servidor maestro y los dos esclavos activos.
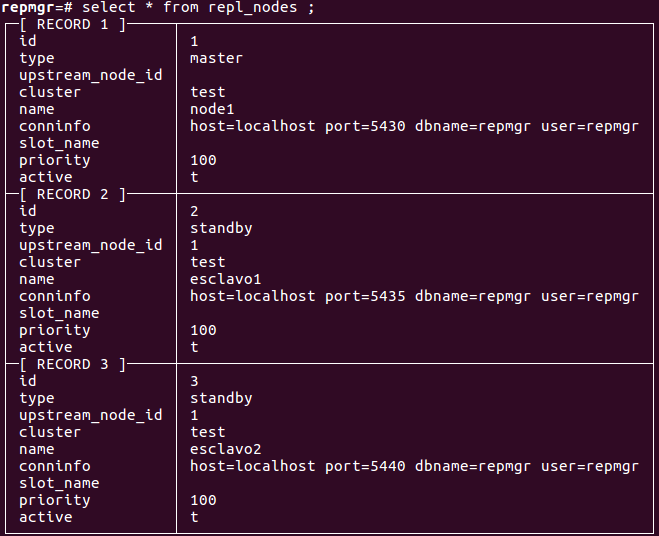
Para realizar una comprobación de failover cuando caiga el servidor principal, se apaga el servidor maestro. Con la siguiente sentencia se puede comprobar que el nodo1 ya no está activo y el esclavo1 se ha convertido en master.

Como podéis ver, hemos conseguido nuestro propósito inicial; cuando nuestro servidor maestro cae, uno de los servidores esclavos lo sustituye como maestro. Podemos decir que tenemos a punto nuestro failover con repmgr.
Esto ha sido todo por esta entrada, contamos con vuestra presencia para nuestras próximas entradas y eventos. Se vienen algunas novedades, atentos postgreras y postgreros!
 Replicación en PostgreSQL, Logical Replication
Replicación en PostgreSQL, Logical Replication Cómo quitar los acentos en Postgres
Cómo quitar los acentos en Postgres